
 Yapay zeka teknolojileri hız kesmeden ilerlemeye ve daha da gelişmeye devam ederken bazı olumsuzluklar görmezden gelinmeye devam ediliyor. Yapay zekanın öncü firması OpenAI, komutlara dayalı olarak video üretebilen yapay zekası Sora’yı geçtiğimiz günlerde kullanıma açmış ve muazzam örnekler yayınlanmıştı. Ancak görünüşe göre firma, Sora’nın eğitiminde oyun içeriklerini kullanmış.
Yapay zeka teknolojileri hız kesmeden ilerlemeye ve daha da gelişmeye devam ederken bazı olumsuzluklar görmezden gelinmeye devam ediliyor. Yapay zekanın öncü firması OpenAI, komutlara dayalı olarak video üretebilen yapay zekası Sora’yı geçtiğimiz günlerde kullanıma açmış ve muazzam örnekler yayınlanmıştı. Ancak görünüşe göre firma, Sora’nın eğitiminde oyun içeriklerini kullanmış. OpenAI, bir süredir yapay zeka modellerinin eğitiminde hangi verileri kullandığını açıklamıyor ve Sora da bir istisna değil. Ancak görünüşe bakılırsa, verilerin en azından bir kısmı Twitch yayınlarından ve oyun içeriklerinden gelmiş.
Sora’nın veri setinde oyun içerikleri var
ChatGPT Plus ve Pro abonelerinin 1080p ve 20 saniyeye kadar çeşitli en-boy oranlarında videolar oluşturmasına izin veren Sora, ilk kez şubat ayında tanıtıldığında OpenAI, modelin Minecraft videoları üzerinde eğittiğini ima etmişti. Etkinlikte bir Minecraft videosu üretilmişti. Ancak oyun içerikleri Minecraft ile sınırlı değil.
Aktarılanlara göre Sora, Super Mario Bros. klonu olan bir video oluşturabiliyor. Hatta Call of Duty ve Counter-Strike‘tan esinlenmiş gibi görünen FPS oyun videoları da üretebiliyor. Sora aynı zamanda Ninja Kaplumbağalar’a benzeyen bir dövüş oyunu videosu da yapıyor.
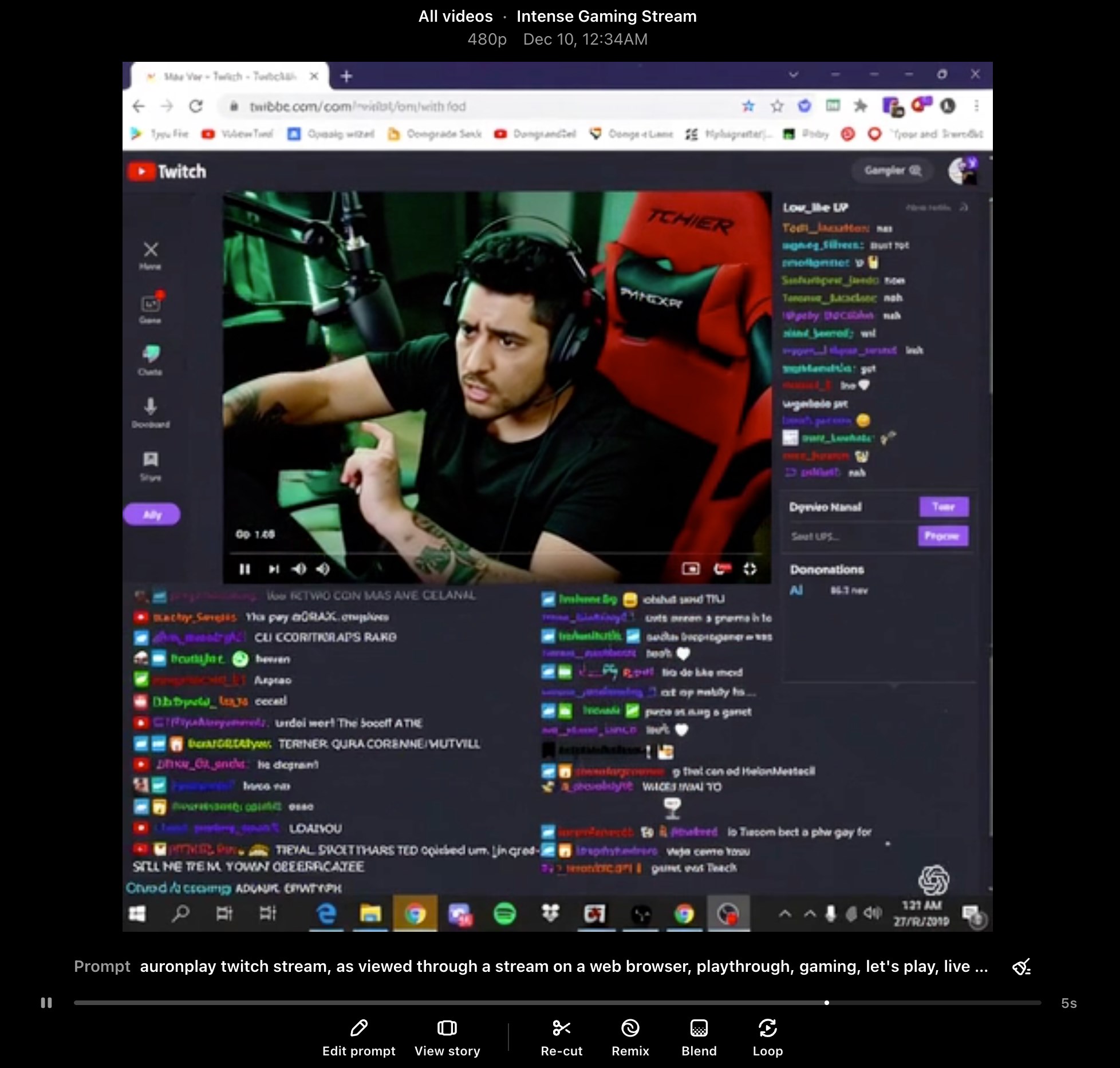
Elbette Sora’nın yaptıkları bunlarla sınırlı değil. Sora, Twitch arayüzüne çok benzeyen videolar da üretebiliyor. Aslında bu, Sora’nın Twitch üzerinde eğitildiğinin somut bir göstergesi; zira yapay zeka modelleri, eğitildikleri veriler üzerinden çıktı sağlıyor. Hatta öyle ki Auronplay adıyla tanınan popüler Twitch yayıncısının kolundaki dövmeyi bile Sora videolarında kullanıyor…
OpenAI, resmi olarak Sora’yı geliştirmek için Shutterstock gibi stok medya kütüphanelerinden lisanslı verilerin yanı sıra “kamuya açık” verileri kullandığını kabul etti. “Kamuya açık” söylemi yapay zeka dünyasında bir ikon haline gelmiş durumda. Zira bunun bağlamı çok geniş. Hangi kamuya açık veri? İnternette ulaşılabilen her şey kamuya açık veri statüsüne mi giriyor? O halde YouTube, Facebook ve Instagram içerikleri de kamuya açık veri olarak eğitimde mi kullanılıyor? Eski OpenAI CTO’su Mira Murati, Sora’nın YouTube, Instagram ve Facebook içerikleri üzerinde eğitilip eğitilmediğini geçtiğimiz aylarda açık bir şekilde inkar edememişti.
Yasal sonuçları olabilir
 Bununla birlikte OpenAI, Sora’yı oyun içerikleriyle eğittiyse bunun yasal sonuçlarının olacağını belirtmek gerek. Zira bunlar telif hakkıyla korunan materyaller. Evet, Sora’da “Super Mario videosu” diye bir istemde bulunamıyorsunuz zira bunlar filtreye takılıyor. Ancak Mario oyunu için “İtalyan tesisatçı oyunu” tarifini kullanarak videolar üretebilirsiniz. Haliyle Sora bu videoları ürettiğinde telif haklarını ihlal etmiş oluyor. Hatta kimi durumunda hak ihlalleri bir değil, bir den fazla da olabilir. Mesela Sora, Fortnite oyununda bir haritada oynayan birisinin yer aldığı video üretirse en az üç telif hakkını ihlal etmiş oluyor: Epic, haritayı kullanan kişi ve haritanın yaratıcısı. Şimdilik oyun camiasından konu hakkında bir tepki gelmiş değil. Ancak fikri mülkiyet sahipleri ile yapay zeka şirketleri arasındaki tartışmalar giderek büyüyor.
Bununla birlikte OpenAI, Sora’yı oyun içerikleriyle eğittiyse bunun yasal sonuçlarının olacağını belirtmek gerek. Zira bunlar telif hakkıyla korunan materyaller. Evet, Sora’da “Super Mario videosu” diye bir istemde bulunamıyorsunuz zira bunlar filtreye takılıyor. Ancak Mario oyunu için “İtalyan tesisatçı oyunu” tarifini kullanarak videolar üretebilirsiniz. Haliyle Sora bu videoları ürettiğinde telif haklarını ihlal etmiş oluyor. Hatta kimi durumunda hak ihlalleri bir değil, bir den fazla da olabilir. Mesela Sora, Fortnite oyununda bir haritada oynayan birisinin yer aldığı video üretirse en az üç telif hakkını ihlal etmiş oluyor: Epic, haritayı kullanan kişi ve haritanın yaratıcısı. Şimdilik oyun camiasından konu hakkında bir tepki gelmiş değil. Ancak fikri mülkiyet sahipleri ile yapay zeka şirketleri arasındaki tartışmalar giderek büyüyor. 

